Even if you have been using the GCC suite of compilers heavily for years, it is unlikely you have had to create a Linker Script. Linker Scripts are needed when fine-grained control over the memory layout of an executable is required. Most C/C++ code is compiled to an application or service for a specific OS platform, so memory layout is both pre-defined and generally pretty relaxed.
This is not the case for Bare Metal code. When developing for bare metal, the location of the entry point for the code and the locations of global statics, the stack and possibly the heap must be specified. There is no OS or OS Memory Model to be used. The Linker Script defines the foundation of a bare metal code memory model to be used in the output image.
What the Linker Does
The role of the Linker in creating an executable image is to take a collection of input files that contain ‘segments’ and ‘symbols’ and combine those ‘input segments’ into ‘output sections’ of the final image – while also determining the correct value for various unresolved symbols in the ‘input segments’. Additionally, symbols can be defined in a Linker Script and those symbols will be available to source code. Examples of that kind of symbol resolution appear in the example script.
‘Input segments’ are generated by the compilers or assemblers generating the object files linked together to form the output image. As you progress below, ‘segments’ are in object files and ‘sections’ are generated by the linker. Since the code for my bare metal Aarch64 OS is C/C++ (with a little assembly) the C/C++ Memory Model must be used.
Example Linker Script
Linker scripts use the LD Command Language. It is *mostly* specification, there are not if/then style conditionals, though it is possible to test if a symbol is defined. The only required element of a linker script is at least one SECTION. Sections describe the memory layout of the output binary. LD documentation may be found here.
Below is a linker script from a bare metal OS I have been tinkering with for the Aarch64 on the Raspberry Pi. It has a bit of complexity but is still simple enough to understand and either edit or extend for your needs.
/*
* This linker script is a template which is run through the C
* Preprocessor so that we can include symbols from C header files.
* Whatever gets included here must include only preprocessor
* directives.
*/
#include "os_memory_config.h"
/*
* Define a memory block for the OS_RAM
*/
MEMORY
{
OS_RAM (rwx) : ORIGIN = 0x00080000, LENGTH = 32M
}
/*
* Now for the sections.
*/
SECTIONS
{
.start : {
. = ALIGN(4);
__start = .;
} > OS_RAM
.text : {
. = ALIGN(4);
KEEP(*(.text.boot)) *(.text .text.* .gnu.linkonce.t*)
} > OS_RAM
.rodata : {
. = ALIGN(4);
*(.rodata .rodata.* .gnu.linkonce.r*)
} > OS_RAM
.data : {
. = ALIGN(4);
*(.data .data.* .gnu.linkonce.d*)
} > OS_RAM
. = ALIGN(16);
.init_array : {
. = ALIGN(4);
__init_array_start = .;
KEEP (*(SORT(.init_array.*)))
KEEP (*(.init_array*))
__init_array_end = .;
} > OS_RAM
.bss (NOLOAD) : {
. = ALIGN(4);
__bss_start = .;
*(.bss .bss.*)
*(COMMON)
. = ALIGN(8); /* BSS end has to be aligned on a double-word boundary b/c the zeroing routine sets double words */
__bss_end = .;
} > OS_RAM
.static_heap : {
. = ALIGN(4);
__static_heap_start = .;
. = . + STATIC_HEAP_SIZE_IN_BYTES;
__static_heap_end = .;
} > OS_RAM
__static_heap_size_in_bytes = __static_heap_end - __static_heap_start;
.dynamic_heap : {
. = ALIGN(4);
__dynamic_heap_start = .;
. = . + DYNAMIC_HEAP_SIZE_IN_BYTES;
__dynamic_heap_end = .;
} > OS_RAM
__dynamic_heap_size_in_bytes = __dynamic_heap_end - __dynamic_heap_start;
.el1_stack (NOLOAD): {
__el1_stack_bottom = .;
. = . + 1M;
. = ALIGN(16);
__el1_stack_top = .;
} > OS_RAM
__el1_stack_size_in_bytes = __el1_stack_top - __el1_stack_bottom;
.el0_stack (NOLOAD): {
__el0_stack_bottom = .;
. = . + 1M;
. = ALIGN(16);
__el0_stack_top = .;
} > OS_RAM
__el0_stack_size_in_bytes = __el0_stack_top - __el0_stack_bottom;
/DISCARD/ : { *(.comment) *(.gnu*) *(.note*) *(.eh_frame*) }
}
__bss_size_in_double_words = (__bss_end - __bss_start)>>3;
As explained at the very top of the script, this is actually a template which is run through the C Preprocessor which then expands the preprocessor directives and generates the final script. The ‘os_memory_config.h‘ file contains the following:
#pragma once #define STATIC_HEAP_SIZE_IN_BYTES 65536 #define DYNAMIC_HEAP_SIZE_IN_BYTES 65536
The advantage of running this template through the preprocessor is that the symbols STATIC_HEAP_SIZE_IN_BYTES and DYNAMIC_HEAP_SIZE_IN_BYTES are now shared in both the linker script and the C/C++ code base – at C/C++ compile time. It is possible to adjust the size of the heaps from a single file, instead of having to remember that there are two places that must be changed.
Inside the Linker Script
Basic LD Command Syntax
Numeric values in a linker script are all integers and C integer operations are permitted. Symbols may be defined in a linker script. Unquoted symbols follow the same rules as C symbols, but symbols may also be quoted – which permits the inclusion of spaces or perhaps reserved words in the symbol.
Probably the most important symbol is the dot ‘.‘ global symbol. The dot symbol represents the current memory location counter maintained by the linker as it is assembling the output image. It may be both read and set.
Semicolons are required after assignment statements and are permitted in other locations but are not required. If you deep dive and end up using ELF Program Headers, semicolons are required there as well.
Standard C block comments are permitted with /* */ delimiters.
Defining a Memory Block
/*
* Define a memory block for the OS_RAM
*/
MEMORY
{
OS_RAM (rwx) : ORIGIN = 0x00080000, LENGTH = 32M
}The snippet above defines a memory block named OS_RAM of 32 megabytes in length, starting at the physical location 0x00080000 which may be read, written to an executed. This location is not an accident – it is the place where the RaspberryPi boot loader loads the OS image. There are additional attributes that can be specified for a memory block and are described in the GCC LD documentation for Memory Layout.
LD permits only a single MEMORY declaration but multiple blocks may be defined in the declaration. It is an optional declaration, if it does not exist, the linker assumes there is sufficient memory for the image.
Defining a Simple Memory Section
SECTIONS
{
.start : {
. = ALIGN(4);
__start = .;
} > OS_RAM
Above is the start of the script section specifications and a simple memory section called ‘start’ which is required to start on a 4 byte aligned memory address. The ‘.’ location counter is set to the next four byte aligned location with . = ALIGN(4) and is then read and assigned to the global variable __start with the __start = . statement.
At the end of the section specification, the > OS_RAM directive tells the linker to assign this section to the OS_RAM memory block defined previously in the script. As successive sections are assigned to this block, it will fill. If the size of the sections assigned to the block exceed the 32M size of the block, the linker will exit with an error.
Defining a Section as a Group of Compiler Defined Segments
The C and C++ compilers define code and/or data segments. A section in a linker script usually defines a collection of input segments that are to be grouped into a single section of memory in the output image. An example follows:
.text : {
. = ALIGN(4);
KEEP(*(.text.boot)) *(.text .text.* .gnu.linkonce.t*)
} > OS_RAM
.rodata : {
. = ALIGN(4);
*(.rodata .rodata.* .gnu.linkonce.r*)
} > OS_RAM
The .text section specification contains the KEEP statement in addition to a regular segment inclusion specification. KEEP is not documented in the GCC LD man pages (I have no idea why) but what it does is includes those segments into the linker section and marks them as ‘used’ even if they are not referenced anywhere else in the input object files. Unreferenced input segments will be eliminated as dead code by the linker, unless those segments as identified to be kept. In this case, we need to be sure the .text.boot segment is retained.
The .rodata section includes read only segments defined in the input object files.
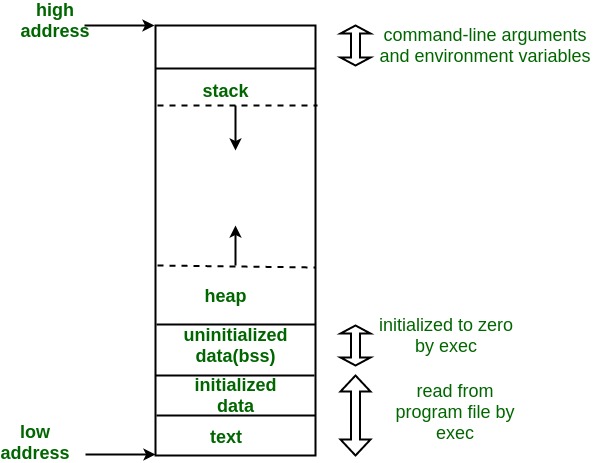
The text segment of a C or C++ program is typically the object code to be executed. The C memory model is illustrated below and the different segments can be found in section declaration statements in the Linker Script.

{kind=link}
The .rodata and .data linker sections are generally the ‘initialized data’ segment of the map.
Wildcards in Section Specifications
The example above contains a couple different uses of the ‘*’ asterisk as a wildcard. When specifying a segment from an input file be assigned to a segment, the actual syntax is ‘foo.o (.input1)‘ where ‘foo.o‘ is the name of an input object file and .input1 is a segment in ‘foo.o‘. If you know that you will have multiple input files with a .input1 segment, then the file specification can be replaced with a wildcard: ‘*(.input1)‘ – which specifies that any .input1 segment in any input file should be included in the output image.
Segment names may also be wildcarded. For example: ‘*(.input*)‘ specifies that any segment that starts with ‘.input‘ in any input file should be included in the output. In this case, segments .input1, .input2, .input345 will be assigned to the linker section. The linker handles wildcards much like the Unix shell with ‘?’ for single characters, ‘[chars]’ for membership and ‘-‘ for range (i.e. ‘[a-z]’).
C++ Static Variable Initialization
Given the object oriented nature of the C++, there needs to be a mechanism to initialize global class instances *before* program execution. In the Linker Script we see this in the .init_array section.
. = ALIGN(16);
.init_array : {
. = ALIGN(4);
__init_array_start = .;
KEEP (*(SORT(.init_array.*)))
KEEP (*(.init_array*))
__init_array_end = .;
} > OS_RAMIn the snippet above, memory is aligned to a 16 byte boundary before the .init_array section is declared. Then we insure we have 4 byte alignment (should be the case after the prior alignment anyway) and define the __init_array_start symbol as the current memory location. The .init_array segments from the input object code are then assigned to the segment and then a second symbol __init_array_end is set to the new value of the memory location counter.
The __init_array_start and __init_array_end symbols may be referenced in object code and will be linked into the output image. In the Aarch64 startup code, C++ globals are initialized as the last step before jumping to the start of the ‘kernel main’ function. The init array is just a list of void functions that initialize a global static when called. Therefore, all the assembly language does is starts with __init_array_start , gets a 4 byte address, jumps to it, and then moves to the next sequential address until __init_array_end is reached.
// Initialize the C++ statics
initialize_cpp_statics:
adrp x19, __init_array_start
add x19, x19, :lo12:__init_array_start
adrp x20, __init_array_end
add x20, x20, :lo12:__init_array_end
cmp x19, x20
beq branch_to_kernel_main
loop_for_next_static_initializer:
ldr x0, [x19], 8
blr x0
cmp x19, x20
bne loop_for_next_static_initializer
// Jump to the kernel main function, must have C style linkage
branch_to_kernel_main:In the C memory map, the C++ intialization array is assigned to the ‘initialized data’ portion of the map.
The BSS Section
In the C memory map there is the ‘uninitialized data segment’ called ‘bss’ which is also referenced in the Linker Script. The bss segment is not initialized as the C++ globals are initialized above but the whole section must be set to zero. The relevant section of the Linker Script is below:
.bss (NOLOAD) : {
. = ALIGN(4);
__bss_start = .;
*(.bss .bss.*)
*(COMMON)
. = ALIGN(8); /* BSS end has to be aligned on a double-word boundary b/c the zeroing routine sets double words */
__bss_end = .;
} > OS_RAM
__bss_size_in_double_words = (__bss_end - __bss_start)>>3;There is a similar pattern here. Align the program counter to a 4 byte boundary, set the __bss_start symbol to the current memory location, keep a couple other sections labelled ‘bss’ in the input files, align the current location counter to an 8 byte boundary so we can set double words in memory to zero and finally create the __bss_end symbol with the 8 byte aligned location. The __bss_size_in_double_words symbol is also computed in the linker script and can be referenced in code (example below).
The section is decorated with NOLOAD, which instructs the linker that there is no code or data to be placed in the output file for this part of the memory map. This makes sense for the .bss section – as it will all be explicitly set to zero in startup code. Another type of section that might be decorated with NOLOAD would be ROM which exists on the HW platform and can be referenced but does not need to be present in the image generated by the linker.
Aarch64 startup assembly language to zero out the .bss section:
// Clear bss - assume the section is a multiple of 8 bytes long
adrp x1, __bss_start
add x1, x1, :lo12:__bss_start
ldr w2, =__bss_size_in_double_words
cbz w2, initialize_cpp_statics // Skip the loop if the bss section is zero length
loop_for_bss_clear:
str xzr, [x1], #8 // Set 8 bytes at a time - the section in the linker script must match
sub w2, w2, #1
cbnz w2, loop_for_bss_clear
Defining an Empty Section
Sometimes it is helpful to define an empty block of memory in the output memory map. The .static_heap section below does just that.
.static_heap : {
. = ALIGN(4);
__static_heap_start = .;
. = . + STATIC_HEAP_SIZE_IN_BYTES;
__static_heap_end = .;
} > OS_RAM
__static_heap_size_in_bytes = __static_heap_end - __static_heap_start;This section is aligned to a 4 byte boundary and then the __static_heap_start symbol is set to the current memory location and then the value of the STATIC_HEAP_SIZE_IN_BYTES symbol included from the .h file is added to the current location. After the location is advanced, the __static_heap_end is set to the current location. No input segments from the input files are assigned to the section and nothing is kept. This is just a chunk of memory. I guess it could be decorated with NOLOAD but since there are no input segments specified – there will be nothing to load anyway. Finally, the symbol __static_heap_size_in_bytes is computed for potential use in the code. Based on the location in the linker script, this heap will appear just after the bss section of the C memory map.
Final Interesting Bits
The Linker Script contains a couple more semi-duplicative sections which carve out memory for heaps and stacks. The need for two different stacks will be discussed in my post on Aarch64 bootstrapping code. The last part of the script that is worth mentioning is the DISCARD section.
/DISCARD/ : { *(.comment) *(.gnu*) *(.note*) *(.eh_frame*) }The DISCARD section is a ‘reserved’ section which can be assigned input segments from the object code files and which will explicitly remove those segments from the output image. In the example above, anything in any .comment segment will be discarded by the linker and anything in any segment starting with .gnu or .note or .eh_frame will be dropped as well.
Adding the Linker Script to the Link Statement
The code snippet below shows the Makefile specification to process the Linker Script Template with the C Preprocessor, write that file to a new file and then use that new file when linking the output image.
LINKER_SCRIPT_TEMPLATE=link.template.ld
LINKER_SCRIPT=$(BUILD_ROOT)/link.ld
$(ELF): $(OBJ) $(LINKER_SCRIPT)
$(LD) $(LDFLAGS) $(OBJ) $(LDLIBS) -T $(LINKER_SCRIPT) -o $(ELF)
$(LINKER_SCRIPT):
$(CPREPROCESSOR) -Iinclude $(LINKER_SCRIPT_TEMPLATE) -o $(LINKER_SCRIPT)There are a bunch of Makefile symbols above – but the key elements should be apparent.
Where to Find the Code
The Linker Script, Makefiles and source code can be found in my Github repository. I have a prior post on the Makefile design which may also be helpful.